The Ultimate Guide to RAG (Retrieval-Augmented Generation) in 2026
The Ultimate Guide to RAG: Building Smarter AI
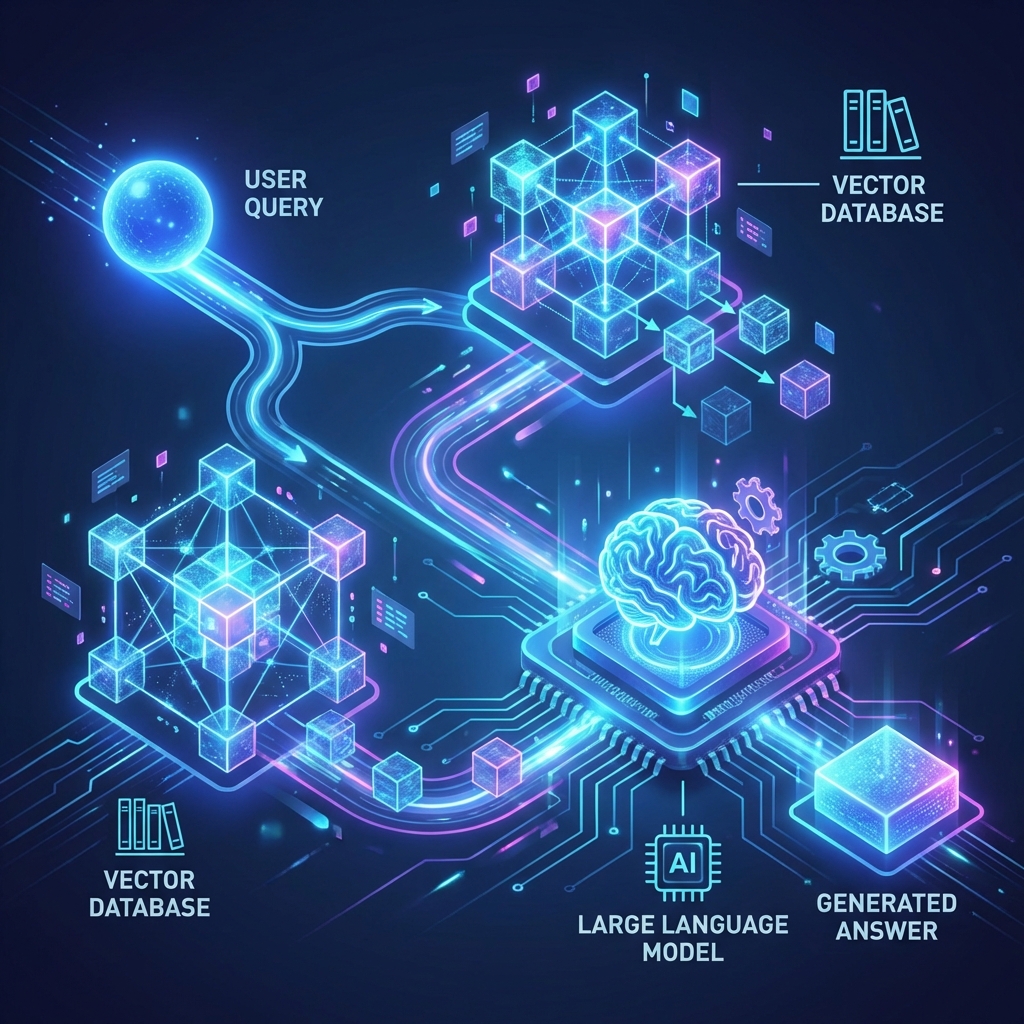
In the rapidly evolving world of Artificial Intelligence, Retrieval-Augmented Generation (RAG) has emerged as the definitive standard for building accurate, knowledgeable, and reliable AI applications. If you've ever used ChatGPT and found it confident but wrong about a recent event, or unable to answer questions about your private company data, RAG is the solution.
This comprehensive guide will take you from the basic concepts to a step-by-step implementation strategy, finishing with real-world industrial use cases.
What is RAG?
Retrieval-Augmented Generation (RAG) is an architectural framework that improves the performance of Large Language Models (LLMs) by dynamically retrieving relevant data from an external knowledge base and referencing it during the generation process.
Think of an LLM as a brilliant scholar who has read every book in the library up until 2023. They are smart, but their knowledge is "frozen" in time.
- Without RAG: If you ask about a 2026 event, the scholar guesses or hallucinates.
- With RAG: You give the scholar a search engine or a specific file cabinet. Before answering, they "retrieve" the relevant documents, read them, and then "generate" an answer based on both their general intelligence and the new specific facts.
The Problem with "Frozen" LLMs
Standard models like GPT-4, Claude, or Llama are trained on massive datasets, but they have two fatal flaws:
- Cut-off Dates: They don't know what happened after their training finished.
- Private Data: They have never seen your company's PDFs, emails, or SQL databases.
RAG solves both by bridging the gap between the LLM's reasoning capabilities and your proprietary, real-time data.
Step-by-Step: How to Create a RAG Application
Building a RAG system involves five distinct stages. Let's break them down.
1. Data Collection (Ingestion)
The first step is gathering the data you want your AI to know about. This could be:
- PDFs & Documents: Employee handbooks, legal contracts, research papers.
- Websites: Scraped documentation, help centers.
- Databases: SQL rows, transaction logs.
2. Chunking
LLMs have a "Context Window" (a limit on how much text they can read at once). You can't just feed a 500-page book into a prompt.
- What to do: Break your text into smaller, manageable pieces called "chunks" (e.g., 500-1000 characters).
- Strategy: Use semantic chunking where possible—keeping related paragraphs together—rather than just blindly cutting every 500 words.
3. Embeddings (The Magic Sauce)
How does the computer know that a chunk about "Apple Pie" is related to a chunk about "Dessert"? It uses Embeddings.
- An Embedding Model (like OpenAI's
text-embedding-3-small) converts text into a long list of numbers (a vector). - Imagine a 3D graph where "Dog" and "Puppy" are close together, but "Dog" and "Car" are far apart.
- You convert all your chunks into these vectors and save them in a Vector Database (like Pinecone, Weaviate, or pgvector).
4. Retrieval
When a user asks a question:
- Convert their question into a vector using the same model.
- Search your Vector Database for the chunks that are mathematically closest (Cosine Similarity) to the question's vector.
- Retrieve the top 3-5 most similar text chunks.
5. Generation
Finally, you construct a prompt for the LLM:
"You are a helpful assistant. Answer the user's question using ONLY the context provided below.
Context: ... [Insert Retrieved Chunk 1] ... ... [Insert Retrieved Chunk 2] ... ... [Insert Retrieved Chunk 3] ...
Question: [User's Question]"
The LLM reads the context and generates an accurate, grounded answer.
Industrial Use Cases
RAG is not just a theoretical concept; it is powering major enterprise transformations across industries.
1. Legal Document Analysis
The Challenge: Law firms have millions of case files, contracts, and precedents. Finding a specific clause across 10,000 documents is a nightmare. The RAG Solution: Lawyers can ask, "What is the standard indemnity clause we used for software SaaS agreements in 2024?" The system retrieves relevant past contracts and summarizes the standard language in seconds, saving thousands of billable hours.
2. Medical Diagnosis Support
The Challenge: Doctors need to keep up with thousands of new research papers published daily. The RAG Solution: A medical RAG system ingests the latest journals (The Lancet, JAMA). A doctor can ask, "What are the latest contraindications for Drug X in patients with kidney failure?" The system retrieves the specific study findings, cites the source, and provides a summarized answer, ensuring evidence-based medicine.
3. Customer Support Automation
The Challenge: Support agents spend 40% of their time searching for help articles or technical specs. The RAG Solution: When a customer asks a question, a "Support Copilot" instantly retrieves the correct page from the technical manual and drafts a response for the agent. This reduces Average Handling Time (AHT) and ensures consistent answers across the team.
4. Codebase Documentation
The Challenge: Onboarding new developers to a massive legacy codebase is difficult. The RAG Solution: Ingesting the entire codebase and internal wiki into a RAG system allows new devs to ask, "How is authentication handled in the payment microservice?" The system retrieves the specific auth files and documentation, explaining the flow and pointing to the exact lines of code.
Ready to Build?
RAG is the bridge between generic AI and specific value. By implementing the 5-step pipeline—Ingest, Chunk, Embed, Retrieve, Generate—you can create applications that are not just smart, but specialized experts in your domain.
FAQ
1. Is RAG better than Fine-Tuning?
For adding knowledge, yes. RAG is cheaper, faster, and allows you to update data instantly (just add a document). Fine-tuning is better for teaching the model a new behavior, style of speaking, or very specific format, but it is expensive and hard to update.
2. Which Vector Database should I use?
For beginners, Pinecone is excellent because it's managed and easy to start. For open-source or local development, ChromaDB or pgvector (PostgreSQL) are fantastic choices.
3. Can RAG work with private data?
Absolutely. That is its primary use case. Since the data stays in your database and is only injected into the prompt transiently, it is far more secure than training a public model on your proprietary data.